안녕하세요. JohnComputer 입니다.
오늘은 한번 GPT를 이용해서 로또 번호 예측 시스템을 만들어 보려고 해요.
아래는 GPT와 빅데이터 분석에 대한 글들이 있어
로또 예측기를 바로 만들고 싶은 분들 (하) 편을 바로 보세요.
| 6개의 무작위 숫자를 가진 여러개의 행의 파일이 CSV안에 있어 이 데이터들을 활용해서 다음에 나올 숫자를 예측하는 시스템을 만들고 싶은데 ML 또는 빅데이터 분석을 이용하여 데이터를 예측하고 싶어 어떤 모델을 사용하면 좋을까? |
사실 GPT는 프롬프트 즉, 명령을 어떻게 내리냐에 따라서
정말 다른 답변을 주게 됩니다.
질문을 잘 하는게 중요 합니다.
숫자를 예측 하는 모델
| 기초적인 회귀 모델 (Basic Regression Models) |
|
| 시간 시계열 모델 (Time Series Models): |
|
| 머신러닝 모델 (Machine Learning Models): |
|
| 딥러닝 모델 (Deep Learning Models): |
|
예측 모델 개발 과정
1. 데이터 전처리:
- 결측값 처리, 이상치 제거 및 데이터 정규화 등의 전처리 작업을 수행합니다.
- 각 행의 6개의 숫자를 적절한 형태로 변환하여 모델에 입력할 수 있도록 준비합니다.
2. 특징 엔지니어링 (Feature Engineering):
- 과거 데이터로부터 유의미한 특징을 추출합니다.
- 이동 평균, 누적 합계, 차분 등 다양한 통계적 특징을 생성할 수 있습니다.
3. 모델 선택 및 학습 (Model Selection and Training):
- 위에서 언급한 모델 중 하나를 선택하여 데이터를 학습시킵니다.
- 교차 검증을 통해 모델의 성능을 평가하고, 과적합을 방지합니다.
4. 모델 평가 (Model Evaluation):
- 테스트 데이터를 사용하여 모델의 예측 성능을 평가합니다.
- MSE(Mean Squared Error), RMSE(Root Mean Squared Error) 등의 평가지표를 사용합니다.
5.모델 튜닝 (Model Tuning):
- 하이퍼파라미터 튜닝을 통해 모델의 성능을 최적화합니다.
- Grid Search, Random Search, Bayesian Optimization 등을 사용할 수 있습니다.
6.배포 및 모니터링 (Deployment and Monitoring):
- 예측 시스템을 배포하고 실시간으로 데이터를 수집하여 예측 결과를 모니터링합니다.
- 모델의 성능을 지속적으로 평가하고, 필요시 재학습을 수행합니다.
위에 내용 까지는 GPT가 만들어 준 내용이고
대충 이해를 했다면 역대 당첨 번호를 가지러 가보겠습니다.
역대 당첨결과 CSV파일 만들기
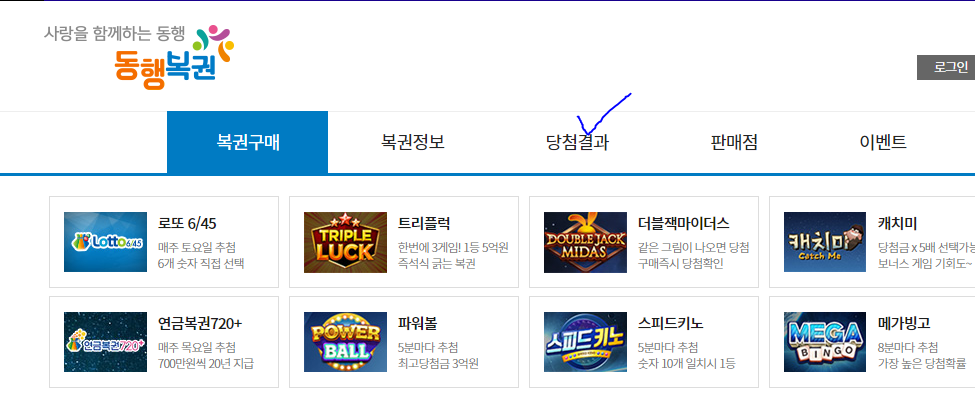

당첨결과 탭을 눌러주시고
하단에 가게 되면 작게 적혀있습니다.
여기서 엑셀 다운로드를 눌러주세요.
이렇게 다운 받은 데이터를 가지고
코드로 가져가게 되면 저희가 불필요한 데이터도 가지고 있게 됩니다.

저는 여기서 불필요한 열들을 모두 지우고 보너스 번호까지도 모두 지울 예정입니다.
이후 CSV 파일로 만들어 주는 작업도 같이 진행합니다.
혹시 CSV 작업된 파일이 필요하다면 댓글 남겨주세요.

모두 작업되면 위와 같은 파일만 남게 됩니다.
이후 작업은 (하)편에서 계속할게요.
'프로그래밍 > IT(비지정주제)' 카테고리의 다른 글
| 윈도우 10 무료 설치 방법 - 포맷 클린 설치 (4) | 2024.10.13 |
|---|---|
| AI 빅데이터 분석을 이용한 로또 번호 예측 만들기 (하) - GPT와 함께 (0) | 2024.07.27 |
| SD카드 완벽하게 지우기 - 로우 포맷 (개인정보 지우기) (1) | 2023.11.02 |
| 슬랙 curl api 호출이 안됩니다 curl (60) error slack webhook (1) | 2023.09.15 |
| VMware 무료 설치하기 + 리눅스 설치까지 (3) | 2023.06.02 |